
A simple demonstration of Apach Spark for data analysis running on AWS EMR (Elastic Map Reduce) cluster setup. I’m using pyspark but its very similar to Spark scala or Java (I did it on both Python and Java but for this writeup I am using Python)
AWS EMR is a managed big data platform that provides a cluster to run jobs across cluster without having to worry about setting up the cluster, etc. We can use Spark & other frameworks on EMR. Not dwelling too much in to details of EMR or Spark jobs in this writeup, there are enough materials on official sites or other blogs. This is mostly a log of things that I did and managed to run the setup/jobs for my need for demo purpose.
Not going in to details of basic AWS account, billing, etc setup that you will need, before getting started you will need;
- An AWS account with billing setup - some of the services that I’ve used are chargable by AWS, so should delete when done
- Have your spark job ready and tested locally (on your laptop or some single node machine)
Setup a AWS S3 bucket
Create a S3 bucket to store your input data files, outputs, logs, configs, etc.
Setup a AWS key pair
Under EC2 > Key Pairs create a key pair with some name like emr-key. This should generate a key (emr-key.pem) file and gets downloaded. Save it somewhere safe on your local machine.
Setup AWS EMR Cluster
Search for EMR on AWS console, then create cluster. Select/configure hardware, software and security required for the cluster.
On the next screen, Go to quick options.
Then select required hardware.
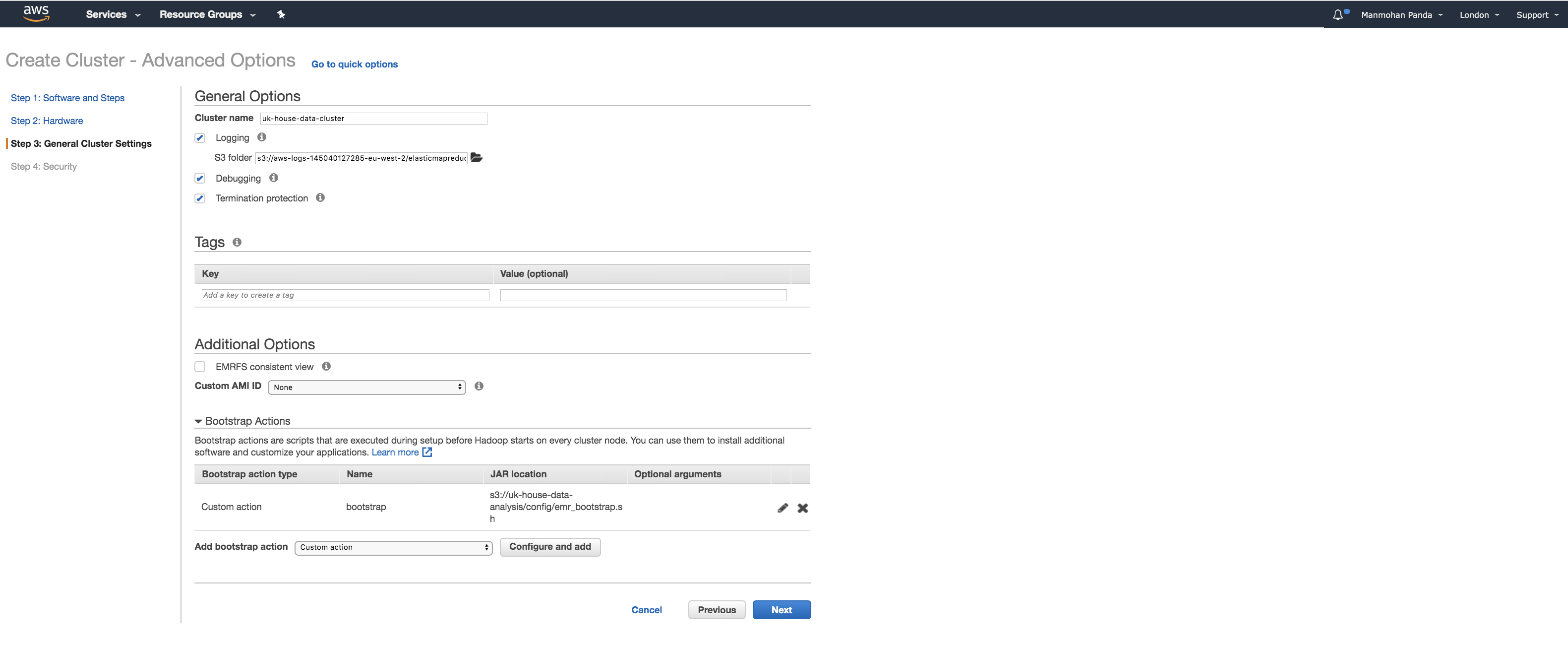
Provide name of the cluster and in my case added a custom config to initialise optional software needed for future.
Add security key pair;
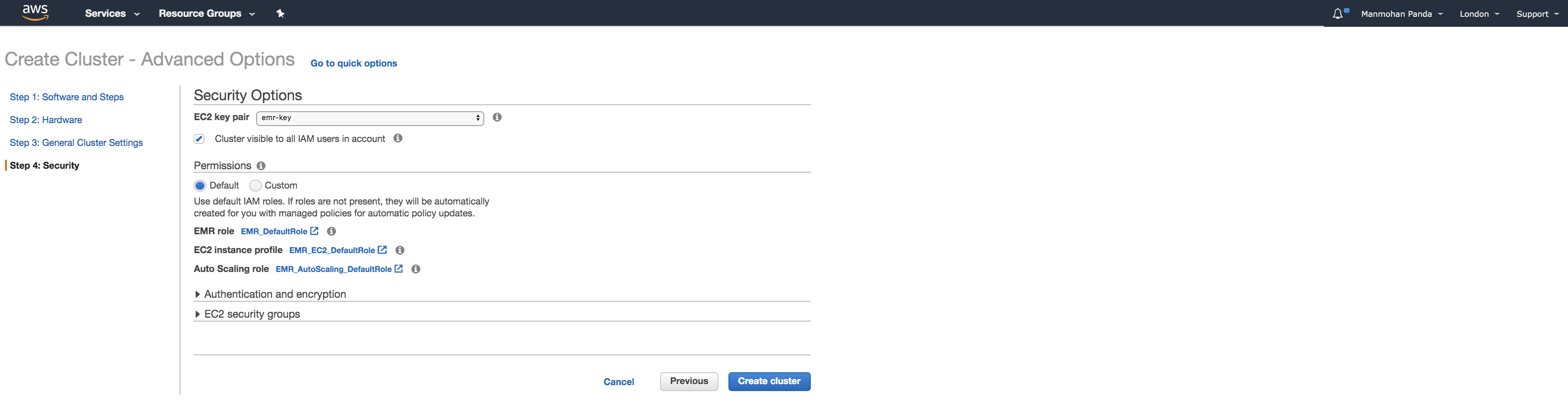
Then once you hit Create cluster it should then start, bootstrap any custom actions and start your cluster i.e. in our case 1 master and 2 worker/core nodes.
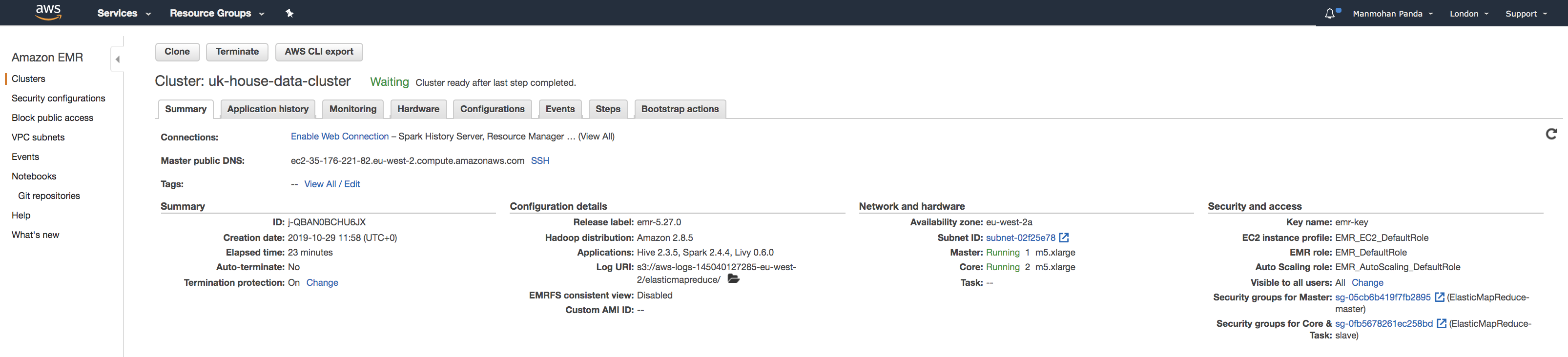
CLI command to create EMR Cluster
aws emr create-cluster --name "Spark cluster for uk house data analysis" \
--release-label emr-5.24.1 \
--applications Name=Spark \
--log-uri s3://<bucket_name>/logs/ \
--ec2-attributes KeyName=emr-key \
--instance-type m5.xlarge \
--instance-count 3 \
--bootstrap-actions Path=s3://<bucket_name>//config/emr_bootstrap.sh \
--steps Type=Spark,Name="Spark job",ActionOnFailure=CONTINUE,Args=[--deploy-mode,cluster,--master,yarn,s3://<bucket_name>/analysis_job.py] \
--use-default-roles \
--auto-terminate
Running Job with JupyterLab notebook
From the left side panel create a JupyterHub notebook and link to the newly created cluster.
Then run job, and you can see status of the progress -
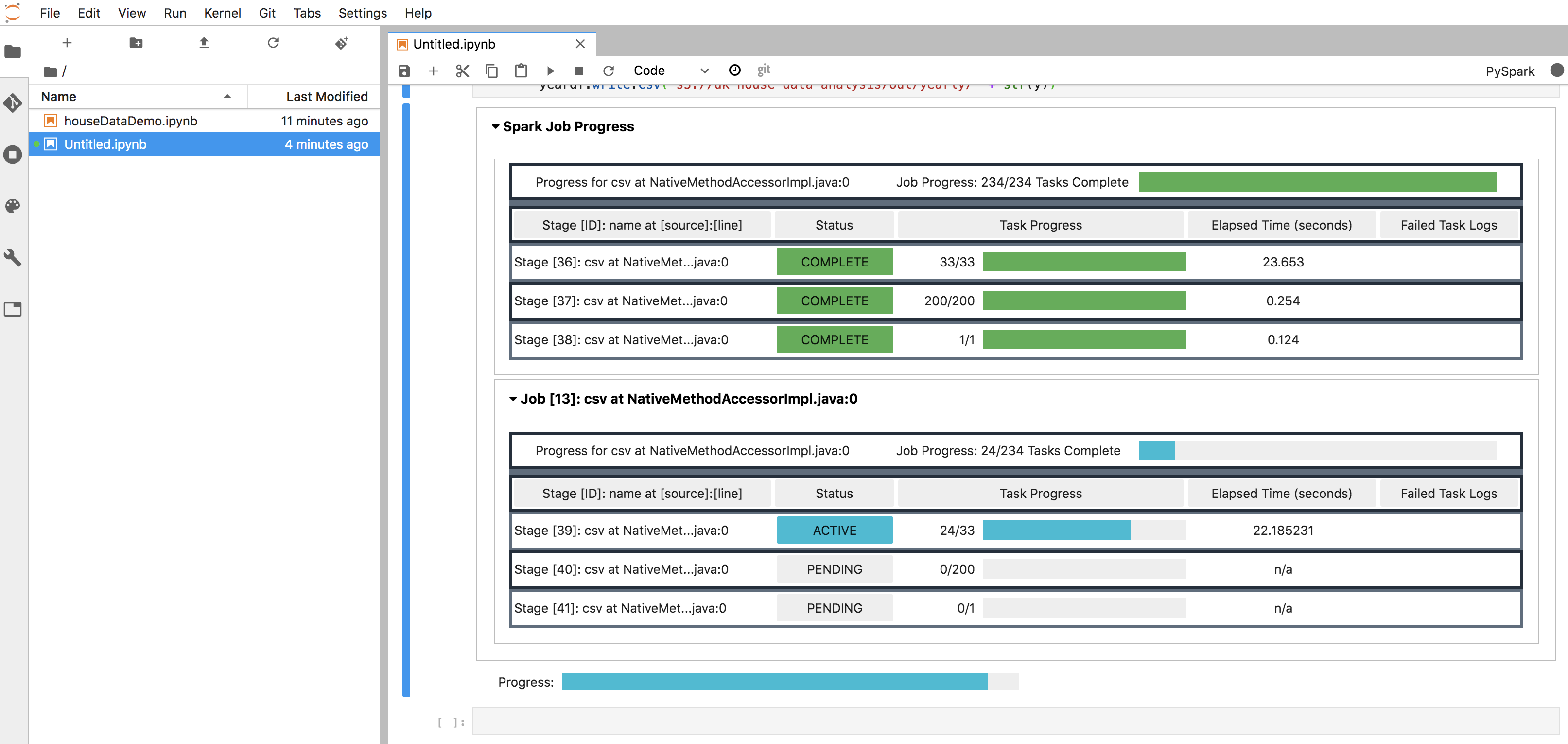
Example code for data processing and some graph building - https://github.com/manmohanp/machineintelligence/tree/master/uklranalytics
EMR Cluster Stats
And once the job is fully complete you can also view EMR cluster stats -
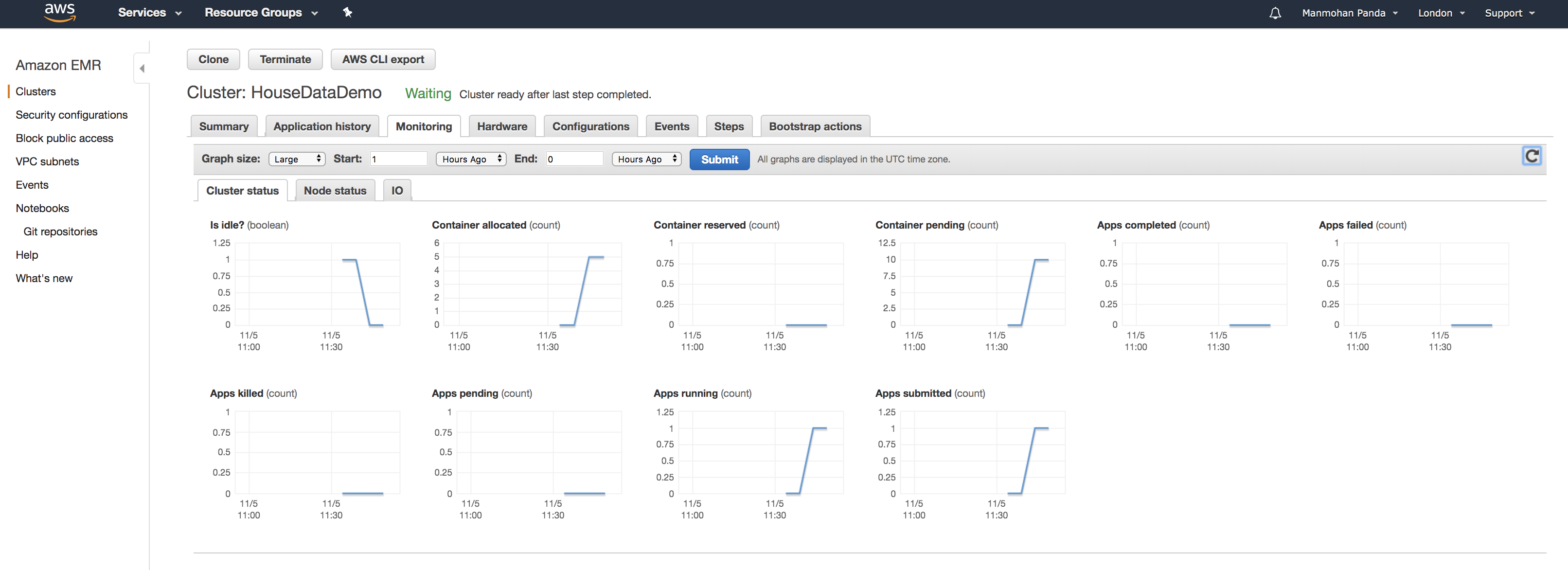
I had about 24 years of data of about 24 million records (4.3 GB) data.
Output - graph based on analysed data